Introduction
RL기본기부터 시작해서 어느 덧 다섯번째 포스팅까지 오게 되었다. 역시나 일종의 시리즈 물을 순서대로 보지 않았다면 계속해서 반복되는 지난 포스팅부터 시작해주길 부탁한다.
드디어 우리는 Grid environement에서 벗어나 연속적인 환경에서도 agent가 $s$를 받아들이고 적절한 $a$를 취할 수 있도록 neural network를 적용한 RL문제를 푸는데 성공하였다. 기억하는가? 지난 포스팅의 CartPole문제 알고리즘은 neural network를 이용했지만 큰 줄기로 Off-policy방식을 채택했었다. 해당 방식은 TD-error를 optimize시키는 과정에서 exploration의 문제가 이슈되는 만큼 더 개선시킬 여지가 많은 알고리즘이다.
이번 포스팅에서는 Q-function기반 학습법(이하, Q-learning) SOTA의 뿌리가되는 DQN알고리즘을 리뷰해보고 CartPole에 적용시키는 예시를 살펴보겠다.
DQN
DQN[1]은 우리나라에 ‘머신러닝’의 센세이션을 불러왔던 RL agent 알파고의 토대가 되는 아이디어다. Nature에 등재된 논문에서 Atari-breakout(벽돌깨기)문제를 인간보다 잘 해결해낸 RL agent를 어떻게 만들었는지 그 과정을 살폈는데 지금까지 우리가 공부해온 RL의 개념들이 적용되어있다. DeepMind사에서 개발했고 실제로 Atari-breakout을 플레이하는 영상이 youtube링크에 있으니 시청해보기 바란다. 인공지능이 정말, 확실히 게임을 잘한다는 느낌을 지울수 없을 것이다. 본 블로그에서는 Neural network모델을 작성한다던가 Objective function을 구성해서 parameter를 업데이트하는 과정을 빼고 리뷰하지 못했던 부분을 체크하고 넘어가도록 하겠다.
!
알고리즘 중에서 Replay memory라고 하는 부분이 아마 생소하리라 예상한다. 이 부분은 코딩을 할때 Target으로 삼아야하는 Target network와 학습으로 삼아야할 Main network를 분리하기 위한 작업이다. 필자는 개인적으로 이 부분이 잘 이해가 가지 않았다. 첫째, 왜 Replay memory라는 버퍼를 따로 만드는가? 그리고 왜 Target network와 Main network를 따로 분리하는가? 부분이었다. 혹시나 필자와 같은 질문을 가질 독자분들도 계실법하니 이 질문에 대해 대답을 하겠다.
-
전자는 TD알고리즘의 약점인 High-Bias & Low-Variance의 특성을 해결하려는 전략이다. 바로 앞의 몇 step앞의 $s$를 가지고 미래를 예측하는 학습방식은 큰 학습 과정으로 봤을때 부적절할수 있는 단점이다. 그래서 논문의 저자들이 시도한 방식으로 그동안 학습해왔던 정보들을 기억하고 임의로 학습했던 정보를 추출하여 현재와 과거의 모든 상황을 골고루 살펴보고자 했던 의도가 숨겨진 부분이었다.
-
후자의 질문에 대답은 지난 포스팅에서 “최적화 과정으로 agent가 계산하는 Q-function의 TD target에서의 Q-function이 부분에서
detach()를 취하지 않으면 gradient graph계산과정으로 인해 동시에 업데이트 된다”는 언급으로 대신한다. 즉, 정답을 맞추기 위해서 gradient descent를 취한건데 정답 자체가 바뀌는 상황을 방지하기 위함이라고 말했었다. 따라서, network를 따로 설정하는 질문은 TD target을 고정시키기 위함이며 적절한 주기마다 $\text{Target network} \leftarrow \text{Main network}$로 업데이트 하는 과정을 겪게 된다.
DQN 알고리즘이 개선된 부분은 이 정도로 요약하면 되겠다. 그러면 이제 CartPole문제를 DQN을 이용해서 해결해보고 Off-policy Q-learning방식과 비교해 보도록하자.
DQN tutorial
해당 코드는 Pytorch 튜토리얼 페이지[2]의 내용을 상당부분 발췌했음을 밝힌다. 미리 밝히건대 Pytorch 튜토리얼 페이지도 DQN을 통한 CartPole을 풀고있지만 $s$를 gym에서 제공하는 state가 아닌 화면 자체로 보이는 (이미지)로 인식을 하고 있다는 점을 밝힌다. 필자의 코드 전 부분을 보고 싶으면 링크를 확인해주기 바란다.
- 알고리즘 구조
알고리즘 구조를 만들고 필요한 기능을 채워 넣도록 하자.
# 알고리즘 메인구조 작성 -> 아직 작동못함! def DQN_train(#<입력인자들은 추후에 채웁시다>): # <초기 변수들 지정> # <Capacity에 맞도록 메모리 초기화> # <main network, target network 설정 후 동기화> for epoch in range(epochs): episode_reward = 0 s = env.reset() while True: # Cart가 쓰러질때까지 계속 반복 # <action 추출, Epsilon-greedy> new_s, r, done, _ = env.step(a) # <메모리 push, [s,a,r,new_s,done]> # <메모리 샘플링 및 학습-> 일정 batch크기 이상> # <특정 주기마다 target network <- main network 덧씌우기> s = new_s episode_reward += r if done: break # <학습과정 출력> - Optional return main_model - Replay buffer
DQN의 핵심인 Replay memory를 만드는 구문이다. python의
collection내부의deque를 이용해서 선입선출(FIFO)을 이용하면 편하다. FIFO란 말은 즉슨, 최대용량을 넘어 원소들이 첨가되면 처음에 들어왔던 원소가 밀려나가 buffer에서 없어짐을 의미한다.# 메모리 버퍼를 만듭시다. 메모리마다 [s,a,r,s']의 정보를 업데이트 # 메모리의 최대 용량은 50,000으로 설정 -> 랜덤 샘플링 진행 class memory(object): ''' Replay buffer를 준비합니다. 특별한 경우를 제외하고는 버퍼의 길이는 50,000으로 초기설정을 놓습니다. 기능 1. push: 버퍼의 끝에서부터 원소를 집어넣습니다. 2. sample: 샘플링할 크기만큼 버퍼에서 임의의 원소들을 추출합니다. ''' def __init__(self,capacity=50000): self.memory = deque([],maxlen=capacity) def push(self,*args): ''' 버퍼의 끝에서부터 원소를 집어넣습니다. DQN의 경우 *args는 list형태로써 다음 원소들을 의미합니다. [state, action, reward, next_state, done] ''' self.memory.append(*args) def sample(self,batch_size): ''' batch_size의 크기만큼 buffer에서 기억을 임의 추출합니다. 입력변수 batch_size : 배치사이즈 출력변수 batch_state : 배치 상태 batch_action : 배치 액션 batch_reward : 배치 보상 batch_new_state : 배치 다음상태 batch_done : 배치 종료여부 ''' samples = random.sample(self.memory,batch_size) batch_state, batch_action, batch_reward, batch_new_state, batch_done = [],[],[],[],[] for sample in samples: batch_state.append(sample[0]) batch_action.append(sample[1]) batch_reward.append(sample[2]) batch_new_state.append(sample[3]) batch_done.append(sample[4]) return np.array(batch_state), \ np.array(batch_action), \ np.array(batch_reward), \ np.array(batch_new_state), \ np.array(batch_done) def __len__(self): return len(self.memory) - Main network & Target network
Neural network를 따로 분리시키는 부분이다. 주의! Main과 Target은 완전 별도의 network가 아니다! 최적화가 진행되지 않으면 같은 $s$에서 두 network는 같은 Q-function값을 반환해야 한다. 코드를 통해서 살펴보자.
# Neural network구조는 동일. # main_model = DQN_model() target_model = DQN_model() target_model.load_state_dict(main_model.state_dict())
.load_state_dict를 특정 주기마다 이용해서 target_model을 update시키는 과정을 통해 본질적으로 같은 neural network라는 것을 agent에게 명시해준다. 그래도 후에 optimize하는 과정에서 detach()를 통해 gradient graph에서 확실하게 계산을 배제하는 과정을 잊지 말도록 하자.
- Epsilon_decay 생략
- Main network 학습 학습 부분은 지난포스팅의 학습 부분과 특별하게 달라진 부분은 없다. 다만, Main network, Target network의 차이점에 대해서 주의하도록 하자.
def DQN_loss_update(main_network, target_network, optimizer, batch_data, gamma=0.99):
'''
목표: DQN알고리즘에 맞는 loss함수를 구하고 최적화까지 수행
목적함수: (Reward + gamma*target_Q(s',argmax_a)-main_Q(s,a))**2
주의! 해당 함수를 시행하기에 앞서 메모리 버퍼가 최소한 10000까지는 차올라 있는지 확인
입력변수:
main_network: 메인 agent(neural network)
target_network: 타겟 agent(neural network)
optimzer: optimizer
batch_data: 메모리 버퍼로부터 얻은 기억
gamma: 할인율(default=0.99)
출력변수:
loss: 모니터링을 위한 TD loss
'''
batch_state, batch_action, batch_reward, batch_new_state, batch_done = batch_data
batch_state = torch.FloatTensor(batch_state)
batch_action = torch.LongTensor(batch_action)
batch_reward = torch.FloatTensor(batch_reward)
batch_new_state = torch.FloatTensor(batch_new_state)
batch_done = torch.ByteTensor(batch_done)
Q_current = main_network(batch_state)
Q_current = Q_current[range(batch_state.shape[0]),batch_action]
Q_next = target_network(batch_new_state)
Value_next = torch.max(Q_next,dim=-1).values
target_value = reward+gamma*Value_next
target_value = batch_done*reward+(1-batch_done)*target_value
td_loss = torch.mean((Q_current-target_value.detach())**2)
optimizer.zero_grad()
td_loss.backward()
optimizer.step()
return td_loss.item()
- Target-Main network 덧입히기
특정 주기마다 Main network, Target network을 동기화 시켜준다. 필자는 10번의 업데이트마다 동기화를 시켜주었고 독자들이 해당 값을 변경하면서 어떤 결과가 나오는지 확인하기 바란다.
def target_overlap_main(main_network, target_network,step,overlap_period=10): ''' 목표: 특정 주기마다 target_network의 파라미터를 main_network의 파라미터로 덧씌우기 입력인자: main_network: 메인 agent(neural network) target_network: 타겟 agent(neural network) step: 지금까지 진행된 step overlap_period: 덧씌우기 주기(default=10) 출력인자: * 순서 주의! main_network -> 입력인자와 동일 target_network -> 입력인자와 동일 ''' if step % overlap_period == 0: target_network.load_state_dict(main_network.state_dict()) return main_network, target_network -
학습과정 출력 - 생략
- 주 코드블럭 완성
지금까지 본 코드요소들을 주 코드블럭에 덧입혀서 학습시킬 준비를 완료한다. Session개념을 도입해서 위 메인 학습 코드와는 상이해졌지만 근본은 똑같다.
def session_train(env,memory_buffer,main_network,target_network,update_step): episode_reward = 0 s = env.reset() while True: a = main_network.get_action(s,eps) new_s, r, done, _ = env.step(a) memory_buffer.push([s,a,r,new_s,done]) loss = 0 if len(memory_buffer) >= start_memory_length: batch_data = memory_buffer.sample(batch_size) loss=DQN_loss_update(main_network, target_network, optimizer, batch_data) main_network, target_network = target_overlap_main(main_network,target_network,update_step) s = new_s episode_reward += r if done: break return episode_reward, loss
# 알고리즘 메인구조 작성
def DQN_train(env,main_network,target_network,optimizer,monitoring=True):
'''
이젠 조립합시다, 하이퍼파라미터는 앞서서 설정되었습니다!
입력변수(설명생략)
env,
main_network,
target_network,
optimizer,
start_memory_length,
epochs: 반복횟수(default=1000)
monitoring: 학습과정 모니터링(Total_reward, TD_loss)
출력변수
main_network
'''
global update_step, eps
episode_rewards, episode_tds, episode_epsilons = [],[],[]
update_step = 0
find = False
memory_buffer = memory()
main_network, target_network = target_overlap_main(main_network, target_network,update_step)
for epoch in trange(epochs):
eps = get_epsilon_value(update_step)
episode_epsilons.append(eps)
for mini in range(mini_sessions):
if len(memory_buffer) >= start_memory_length:
update_step += 1
s_reward, s_loss = session_train(env,memory_buffer,main_network,target_network,update_step)
episode_rewards.append(s_reward)
episode_tds.append(s_loss)
if np.max(episode_rewards) >= env._max_episode_steps*0.7:
clear_output(True)
print(f'Agent got solution! Final reward: {s_reward}, at epoch:{epoch}')
display_monitoring(episode_rewards,episode_tds,episode_epsilons)
find = True
break
if find:
break
if monitoring:
clear_output(True)
print('Episode',epoch)
print('Epsilon',eps)
display_monitoring(episode_rewards,episode_tds,episode_epsilons)
return main_model
결과를 모니터링 해보자.
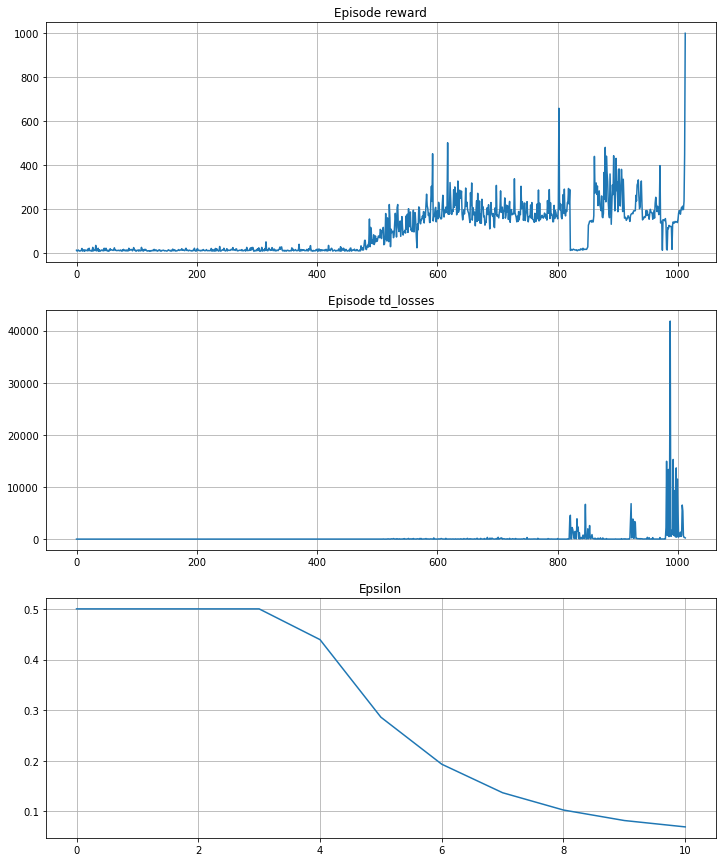
필자는 매 에피소드마다 100번의 세션을 부가하여 학습을 진행했다. 모든 세션에 대해서 학습되는 추이를 보면 $R$ plot은 400째 세션까지는 학습을 안하고 메모리에 임의의 $a$에 대한 경험을 부여하고 학습이 시작되는 구간부터 점차 $R$가 상승하는 구간이 나오더니 한 순간 최대 episode가 나오는것을 확인했다. 이 정도 학습했으면 agent는 충분히 학습을 완료했으리라고 판단하고 학습을 종료하였다. 10번의 에피소드 즈음 학습이 완료되어 상당히 오랜시간동안 Cart가 쓰러지지 않고 버티는 agent의 성능을 확인할 수 있다. 독자들도 코드 전문을 구현해보고 스스로 agent를 만들어 보기바란다. 상당히 재미있다.
다음 포스팅에서는 Atari-breakout을 DQN으로 구현해보겠다. 이론도 중요하지만 코딩도 못지않게 중요하니 머리를 식힌다는 개념으로 다음 포스팅까지만 쉬어가자.
Reference
[1] Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” nature 518.7540 (2015): 529-533.
[2] https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html