
들어가기 전
KAIST의 연구원분들께서 재미있는 논문을 제출했다. 회사에서 풀고자 하는 문제와 적용 될 수 있을 것 같아 스터디하고 정리한 내용을 포스팅을 해본다. 아카이브에 본대로는 내용을 정리하고 구현까지해보려 했으나 우선 아이디어만 요약하고 차차 업데이트해보고자 한다. 이해가 안되는 수식의 전개가 있으나 일단 넘어간다.
논문 정보
- Arxiv 링크
- 저자
- Seong-Hyeon Hwang, Steven Euijong Whang (KAIST)
Paper Contribution
Data augmentation을 적용하는 이유는 Training data의 개수가 제한적이고 data distribution이 좋지 못할때 단점을 극복하기위한 방안이다. 지금까지 Data augmentation으로 연구되었던 바는 mixup(Hongyi Zhang, et al. ICLR 2017)가 대표적이고 후속 연구들도 진행중이다. 다만, 상기 연구들은 Image-classification문제에 대해서 적용되는 바로써 Regression문제에 적용하기에는 무리가 있는 부분이 있다. 원인으로 논문의 Fig 1(a)를 참조하길 바란다.
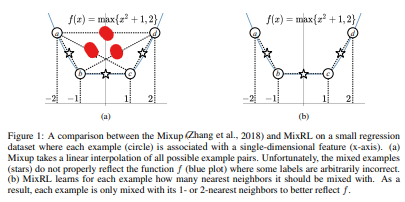
Figure 1. 해석 $f(x) = max(x^2+1,2)$를 추론해야하나 학습데이터셋으로 a,b,c,d 4개의 데이터만 주어져있다.
- Fig 1(a)의 방식은 mixup방식: 4개의 모든 데이터에서 데이터간의 거리에 상관없이 linear interpolation으로 data augmentation을 수행했다. 붉게 칠한 augmented data는 주어진 함수와 무관한 데이터 셋으로 좋지못한 data augmentation을 수행하였다는 것을 시각적으로 보여준다.
- 반면, Fig 1(b)의 방식은 본 paper의 제안방식으로 데이터는 거리에 의존하여 인접한 1개의 데이터로만 data augmentation을 수행하였다. Mixup 방식과는 달리, 타겟으로 삼을 함수와 적절하게 data augmentation이 수행됨을 보인다.
MixRL main idea
1. Policy optimization Reinforcement Learning
RL에 대한 기본적인 설명이므로 생략.
2. Framework
Action: ‘몇 개’의 인접데이터를 이용해서 data augmentation을 진행할것인가
Reward: Regression모델의 validation loss값을 최소화
Figure 3의 해석과 함께 설명
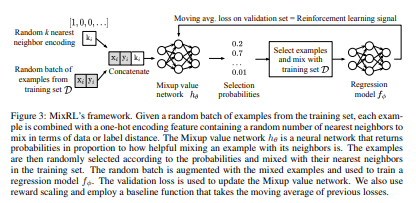
알고리즘 모식도 이해
- 학습데이터 쌍 ($x_i,y_i$)가 있으며, ‘몇 개’의 인접한 데이터를 augmentation시킬 지 지시하는 one_hot encoding 벡터 $k_i$를 concatenate시킨다.
- concat된 데이터를 value network에 출력시켜 value probability를 구한다.
- 최대 probability의 index 번호 ‘i’에 맞도록 ‘i-nearest neighbor’ data augmentation수행
- Augmented data를 이용해 본 regression model을 학습시킨다.
- 학습된 regression모델의 validation loss 값 획득 후 A2C 알고리즘으로 value network를 학습
-
Plus! $\nabla_{\theta} log \pi_{\theta}\left(D^m D^b \right) = \nabla_{\theta} \left( \sum_{D^m}log h_{\theta}(x,y,k) + \sum_{D^b}[1-h_{\theta}(x,y,k)] \right) $
-

Experiments
- RMSE와 R_square를 이용해서 성능이 향상된 정도를 파악
- Dataset으로 No2, 반도체 제조공정에서 사용된 Product, Synthetic, 그리고 Airfoil를 사용했음
- 그 외 MixRL세팅과 다른 지표로 삼을 data augmetation방식에 대한 소개
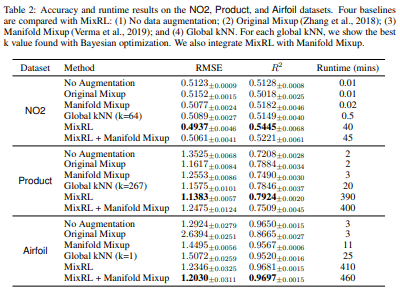
Table 2를 통해 주어진 데이터셋에 대하여 제안된 MixRL의 방식이 가장 낮은 RMSE지표와 가장 높은 R_square값을 보여주었음을 확인
- Ablation study(4.4) {Data, Label, Data+Label} 각 케이스에 대해서 limitation을 조절한 결과, Data와 Label에 대해서 모두 limitation을 걸어준 MixRL의 방식이 가장 좋은 성능을 보여주었음.